Live OCR Processing Analytics
Real-time throughput and accuracy benchmarks from Emed OCR production deployments.
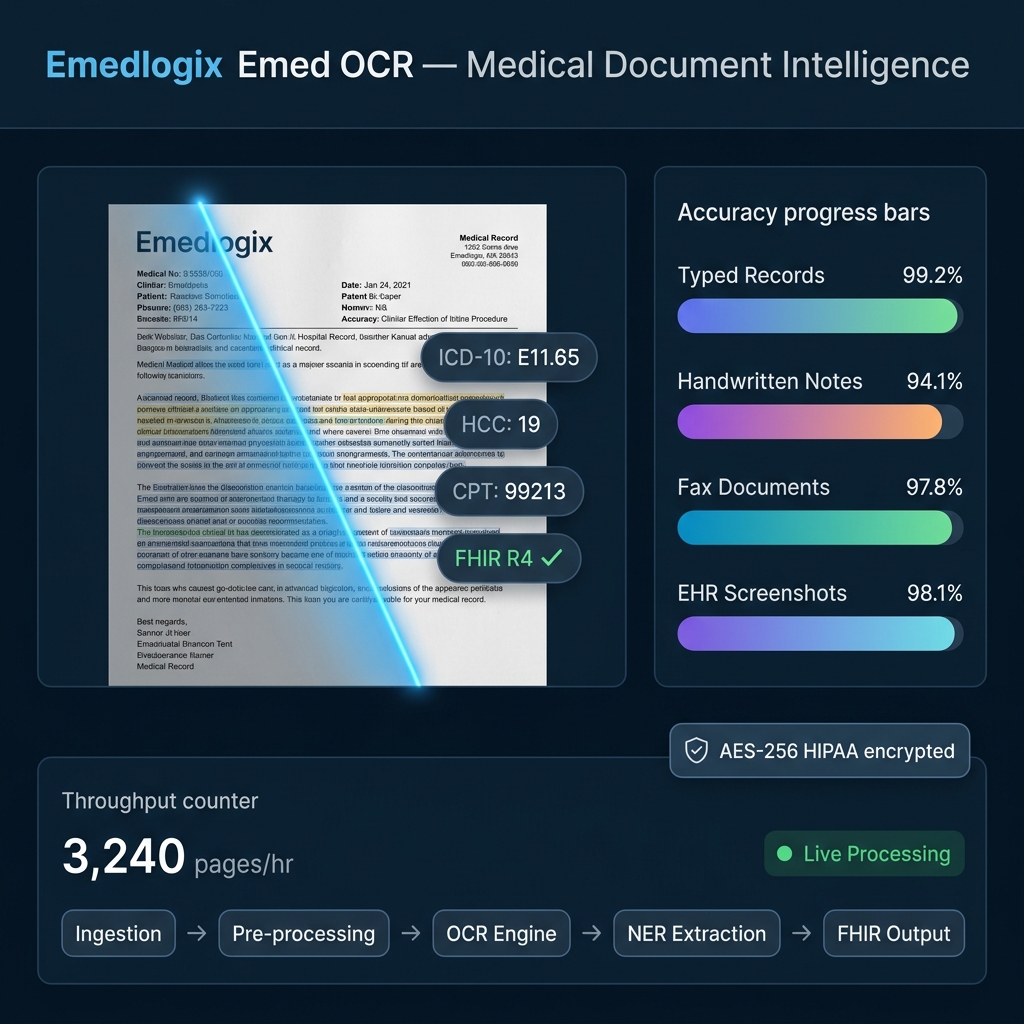
▪ Live Document Scan Preview
Processing: discharge_summary_003.pdf — 99.2% confidence
0
Pages processed in the last hour
Across all active Emed OCR deployments • Updated every 60s
▪ Recognition Accuracy by Document Type
Typed / Printed Records0%
Handwritten Physician Notes0%
Fax Documents0%
EHR Screenshots0%
NER Clinical Entity F10%
0
Pages processed monthly
<0s
Avg. sec per page